这个Kaggle Steel Defect Detection 比赛和上一个我参加的Kaggle SIIM-ACR Pneumothorax Segmentation Challenge时间有点冲突,当我参加并总结完上一个比赛时这个比赛只剩下一个月的时间了。但是一来最近没啥好的比赛参加,而来这个比赛的任务和上一个比赛的任务大致相同。所以和小伙伴商量一下,就参加了一下。
另外,这次比赛的源代码已经释放出来了,具体点这里。
任务介绍
这次比赛的主要任务是从钢材图片中判断钢材是否有表面缺陷,如果含有的话要判断出缺陷类型并定位缺陷位置。也就是说这个任务是一个分类+实例分割的任务。
该比赛只有一个阶段,Public Leaderboard只采用了其中的33%的数据打分并排名,最终的Private Leaderboard采用了最后67%的数据打分并排名。
难点
- 类别不均衡
- 图像分布差别比较大
数据集
这次比赛所采用的数据集为钢铁图片,训练集数目为12568张,阶段测试集数据有1801张。
掩模数据以CSV格式的文件给出,每行数据以ImageId_ClassId,EncodedPixels给出,每一个张图片对应4行数据,也就是说这个数据集有四种缺陷类型。我们需要使用代码将每张图片的所有EncodedPixels均转化为掩模矩阵形式。掩模矩阵通道数为4,第$i$个通道代表该钢铁图片含第$i$类缺陷的情况,其中像素值等于0的位置表示没有该类缺陷,像素值等于1的位置表示有该类缺陷,若该通道的像素值全部为0,则表示该图片没有该类缺陷。
数据分析
基本上每一个Kaggle比赛都会有大佬分析数据集的分布。在这个kernel,有大佬关于这个数据集的分析,感觉特别好,所以就直接拿过来用了。
该数据集含有的缺陷种类有四种,对这四种缺陷分别进行可视化,可视化结果如下:




对于整个训练集,没有任何缺陷的图片总数为5902张,而有至少一种缺陷的图片总数为6666张。两者的比例接近1:1。
统计各类个含有多少张图片,结果如下,可以看到含有第三中缺陷的图片数量特别多,而含有其他缺陷的图片数量偏少。因此这是一个类别不平衡问题。

对至少含有一种掩模的图片含有的类别总数进行统计,结果如下,可以看到基本上所有的图片均含有一类或者两类缺陷。

最后,所有的像素点均属于一种缺陷或者无缺陷,没有一个像素点属于不同缺陷的情况。
数据预处理
数据增强
因为数据集并没有上下左右的区分,所以我们对数据集进行了随机水平翻转和随机垂直翻转,两者的概率均为0.4。
观察下面图片,发现有很多这样的图片一侧或两侧为黑色区域,因此我们对数据集进行了随机平移,概率为0.4。

另外,考虑到数据集中各个灰度图片的亮度、对比度不均衡,我们对数据集进行了直方图均衡化(概率为0.3)、随机Gamma变换(概率为0.1)、随机亮度饱和度变换(概率为0.1)。
最后,为了防止过拟合,我们对数据集添加了模糊处理以及加噪处理。
标准化
数据增强之后,理所当然的需要对数据进行标准化处理,因为我们采用了imagenet的预训练权重,所以使用了imagenet的均值和方差。Kaggle上一名大佬说虽然可能数据集的分布与imagenet数据集的分布差别较大,但是有很多的卷积核尤其是浅层的卷积核提取的是与类别无关的特征,例如边缘、纹理信息等。
数据划分
在之前的博客——Kaggle SIIM-ACR Pneumothorax Segmentation Challenge 总结)文章中已经详细介绍了数据划分的一些基础知识,这里不再赘述。
之前分析过,我们数据集是不均衡的,有大概一半的数据集是没有任何缺陷的,而有一半的数据集是至少有一种缺陷。因此,我们采用了分层交叉验证的方式,使得各个折中训练集以及验证集中没有任何缺陷的数据与有至少一种缺陷的比例大致也为1:1。折数为五折。
模型
模型部分我们主要使用了Unet的网络结构,一方面在上一个比赛中我们使用的为Unet模型,代码写起来比较方便;另一方面,Unet模型的效果确实比较好。关于Unet模型的详细优点在之前的博客中已经有详细介绍,这里不再赘述。
因为这个问题是一个分类加分割问题,根据上个比赛的经验,我们这次模型分为两部分——分类模型以及分割模型。
分类模型
分类模型的主要目的是判断图片是否不含任何缺陷。若图片至少含有一种缺陷,则该图片为正类,否则为负类。
Unet分为两部分——encoder部分和decoder部分。encoder部分即为我们常见模型(如Resnet、Vgg等)的特征提取部分。因此对于不同的encoder,在后面添加适当的分类层即可作为分类模型。至于具体分类层的构造,可以查看我们的代码,这里就不再详细说明了。
分割模型
分割模型的主要任务是将有缺陷图片的具体缺陷种类以及位置定位出来。其输出通道数等于类别数,也就是输出有四个通道,第$i$个通道表示该图片含第$i$类缺陷的情况。
分割模型采用的是Unet网络结构,不同的分割模型主要是backbone的不同。
How to Train model
下面只是阐述以下训练的整体思路,对于不同分类、分割模型的超参数并没有详细给出。具体超参数可以参考我们的代码。
分类模型
分类模型主要有三个,分别是Unet_ResNet34的encoder部分加上分类层、Unet_ResNet50的encoder部分加上分类层、Unet_se_resnext50_32x4d的encoder部分加上分类层。
对于每一个分类模型,加载ImageNet预训练权重,在全部数据集划分出的第一折上进行训练,输入图像的尺寸和原始图像的尺寸一致。优化器使用Adam,学习率采用余弦衰减的策略。因为这是一个二分类问题,因此直接使用了二分类交叉熵损失函数。
分割模型
分割模型也主要有三个,这三个模型主要在于backbone的不同,分别是Unet_ResNet34、Unet_ResNet50、Unet_se_resnext50_32x4d。选择backbone的原则为要在网络的性能和网络的大小之间做一个平衡(网络太大会导致batch size过小,BN层不work)。
我们也尝试过使用unet_efficientnet_b4,但是这个模型虽然参数量不大,但是模型训练特别耗时,训练结果也不是很好,所以就没再使用。
对于分割模型,加载ImageNet预训练权重,在全部数据集划分出的第一折中取出至少有一种缺陷的部分进行训练,输入图像的尺寸和原始图像的尺寸一致。优化器使用Adam,学习率采用余弦衰减的策略。我们这里也采用的是二分类交叉熵损失函数,这是因为
- 考虑到分割模型输出通道数等于类别数,第$i$个通道表示该图片含第$i$类缺陷。也就是说如果我们单独看每个通道的话,均是一个个的二分类任务。
- 这个数据集是类别不均衡的,使用二分类交叉熵损失函数计算每个类别的损失比计算整体损失更有助于解决类别不均衡问题。
感觉这次比赛可以在以下几个方面进一步改进,但是由于时间比较紧张,所以没来得及进一步调试:
- 在损失函数上下文章,比如说损失函数加权,BCE与Dice损失函数的组合等
- 训练分割模型的时候,也可以加载分类模型的encoder部分的权重,而不是加载ImageNet预训练权重,这样可以让分割模型见到更多的数据分布
阈值选取
虽然我们的模型是由分类模型和分割模型组成的,但是由于分类模型使用0.5的默认阈值时在验证集上的正确率通常均高于0.98。因此可以直接使用0.5的默认阈值。因此只需要选取分割模型的阈值即可。
因为我们将这个比赛视为一个个二分类问题,而二分类问题最后一层通常要经过sigmoid函数,将其归一化到[0,1],若是直接用0.5作为正负样本的分割点,效果可能不会很好。因此如何选取合适的像素阈值是这次比赛的一个重中之重。而每张图片可能含有四种缺陷,每一张缺陷之间互不干扰,因此像之前那样针对所有缺陷求一个像素阈值是不合理的,我们的做法是针对每一种缺陷求其最优像素阈值。
另外,正如上面所说每张图片可能含有四种缺陷,每一张缺陷之间互不干扰,因此像之前那样对整张图片求一个最小缺陷像素总数(若一张图片各个缺陷的像素总数小于这个数就判定模型为误判,置该图片为不含任何一种缺陷)是不合理的。观察上面四种缺陷的可视化结果,可以发现某张图片的缺陷通常是成块的,因此对每一个类分别求出最小缺陷像素总数也是不合理的。因此,这次我们采用的是针对每一种缺陷求出其最小连通域,若该图片预测出的这种缺陷某一个连通域小于其最小连通域,则判定该模型对该块区域的该类缺陷预测错误,置该图片的该块区域不含该类缺陷。
阈值用途
这里暂时不说明阈值在模型集成时的作用,以第二个模型为例,阈值的用途如下所示,一图胜千言,感觉下面图已经画的挺详细的了,所以就不在用文字阐述了。
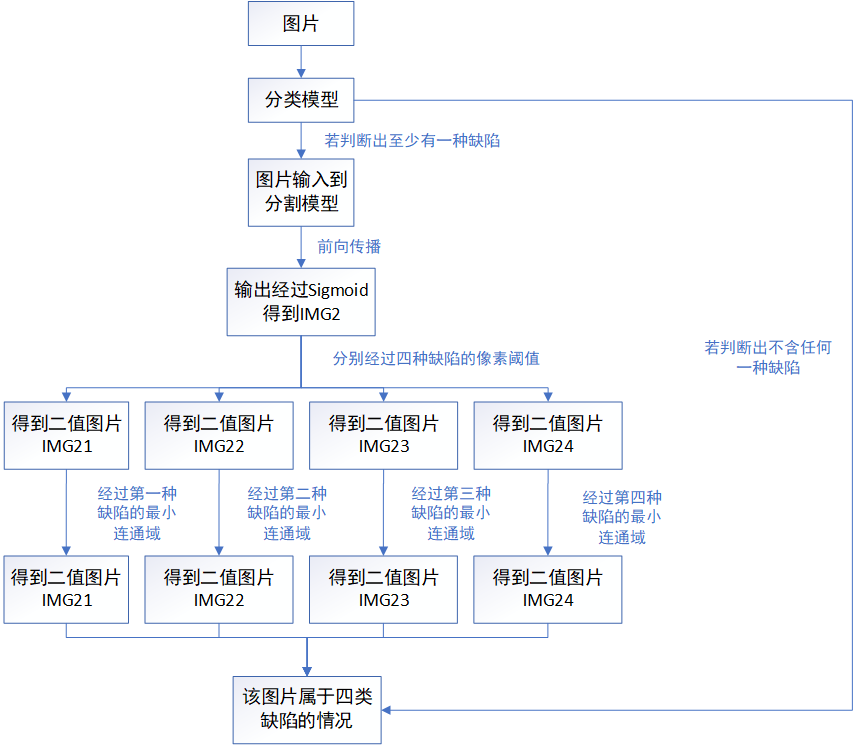
阈值评价标准
首先介绍一下Dice系数的概念。Dice系数:也就是$\frac{2 * \mid X \cap Y \mid}{\mid X \mid + \mid Y \mid}$,$X$为预测出的像素集合,Y为真实标签。值得注意的是,当$X$和$Y$均为空的时候,Dice系数被定义为1。
之前我们分析过,这个比赛数据集很大的一个问题是类别不平衡,因此若是对所有缺陷类选取一个像素阈值以及最小连通域是不合理的,真正的做法是对不同缺陷类选取不同的像素阈值以及最小连通域。阈值评价标准为,针对这个缺陷类别,选择最优像素阈值以及最小连通域组合使得验证集上这个类别的Dice系数最高。
挑选阈值方法
阈值选取的方法主要有两种——网格搜索法以及线性搜索法。网格搜索算法运算量大,但是结果更加精准。
这次写代码之前,我对选阈值的代码进行了架构,要求一次前向传播,完成所有的阈值选取工作,极大的加快了选取阈值的速度,因此这次选取阈值虽然采用了网格搜索法,但是耗时与之前的线性搜索法基本相同。
具体的网格搜索法为——针对每一个缺陷类别,依次遍历该类像素阈值以及最小连通域的候选解组合,挑选出使验证集Dice最高的组合。得到该组合后,缩小像素阈值以及最小连通域的搜索区间,减小步长为之前的$1/2$做精细搜索,得到最终的最优组合。因为有四个类别,所以最终有四个最优像素阈值、最优最小连通域组合。
Ensemble
之前Kaggle的经验告诉我们,集成的效果不一定好。所以这次我们尽早做了集成。并且集成的并不是简简单单的单一模型的不同折,而是不同模型的相同折。另外,这次比赛要求kernel的前向传播时间不得超过一个小时,所以我们就没有采用先集成同一模型的不同折,再集成不同模型的方案。
个人感觉应该集成不同模型的不同折,这样可以让模型见到更多数据,但是因为我们没有时间在另外两折上调试最优结果,因此也就没有集成不同折。
若采用平均法集成,需要计算像素阈值以及最小连通域的均值,而我们要集成不同的模型,计算不同模型的像素阈值以及最小连通域的均值显然不合乎常理。所以就只能采用投票法,对不同分割模型,分别经过各自的最优阈值以及最小连通域得到二值图,对这些二值图按像素点进行投票,得到最后的结果。
而关于如何将分类模型以及分割模型结合起来,有两种方案:
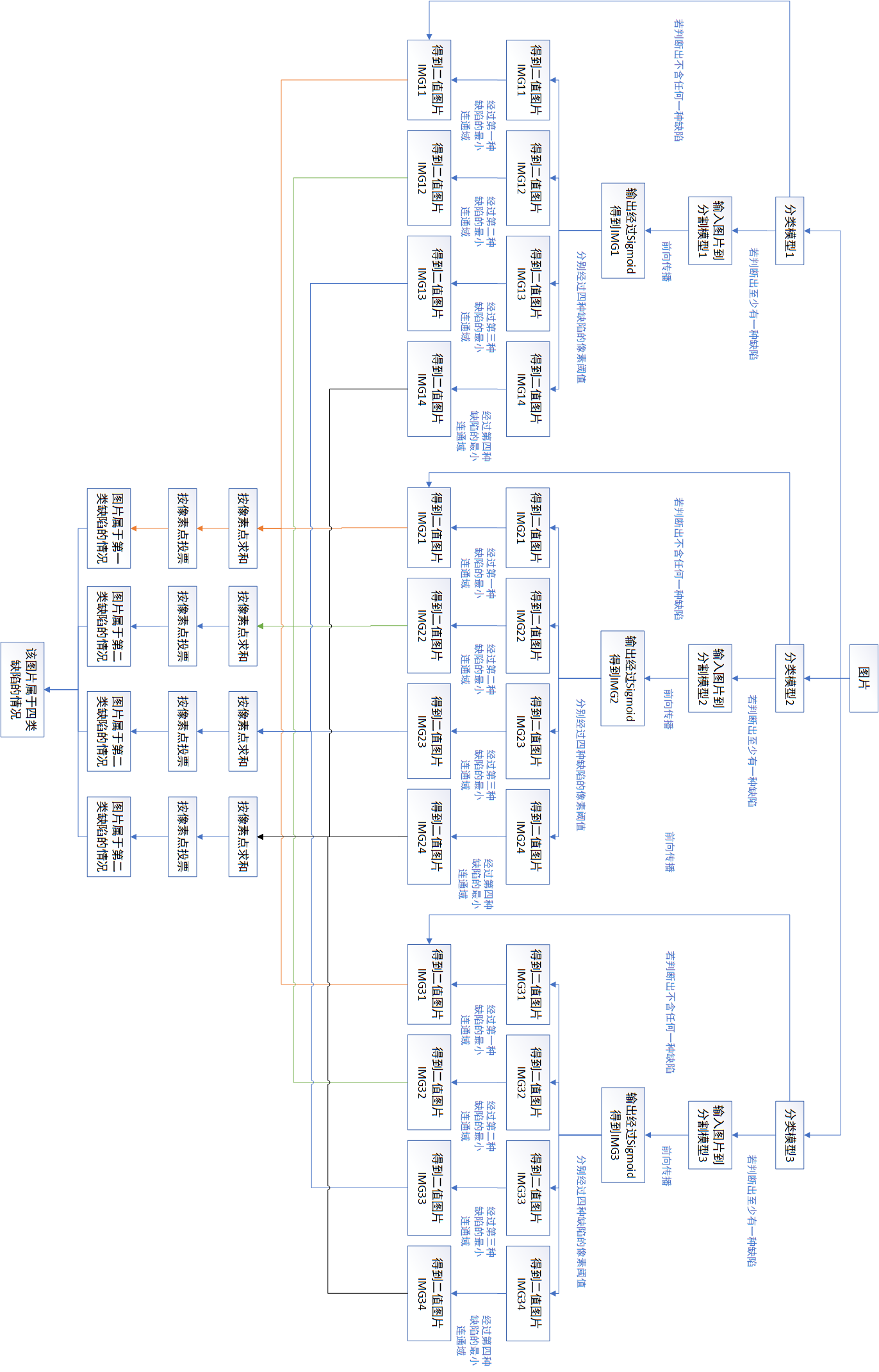
方案一:因为分类模型的特征提取部分和分割模型的encoder部分是一一对应的,因此可以采用图片经过不同分类模型+对应的分割模型+投票的方案。如下图所示,下面图比较长,建议可以竖屏查看。
方案二:考虑到分类的性能对我们的结果影响很大,因此要求分类模型精度尽可能的高,因此可以先将分类模型集成,再将分割模型集成的方案。也就是图片经过不同分类模型+投票+不同的分割模型+投票的方案。如下图所示,下面图比较长,建议可以竖屏查看。
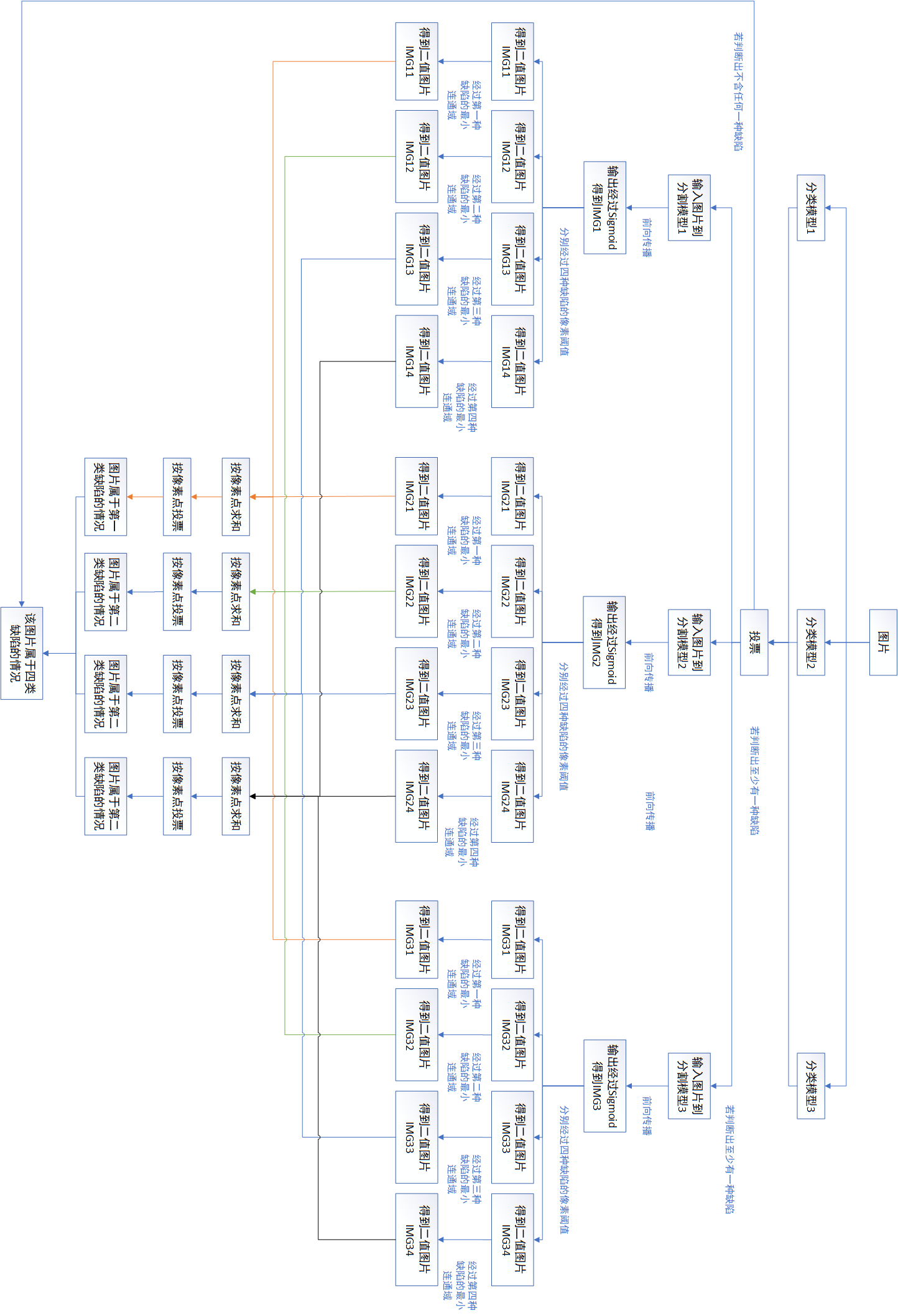
对于本次比赛,我们采用的第二种方案,这是因为想尽可能的让分类的精度更好,避免整张图片漏检的情况。
经验
- 写选阈值代码的时候,尽可能只写一次前向传播,完成阈值选取工作
- 这次虽然代码整体思想和上一个比赛的代码大同小异,但是之前代码函数与函数之间功能杂糅在一块,看起来很乱,改代码也不是很方便。这次我对代码的架构进行了重构,尽量做到代码的高内聚低耦合,尽量减少代码的重复,尽量做到各个函数功能清晰明确。
- 另外,在书写这套代码的时候,对代码命名进行了规范、每一个函数均添加了入口以及出口注释,并形成了习惯。入口以及出口部分对于变量的注释均包含三部分——作用,类型,维度;若阐述不清楚,再添加第四部分——Note。
与金牌差距
在这里,有一位大佬分享了自己的思路,其最优结果可以在私人排行榜得到第一名,他的代码可以在这里找到。
附件
本文中的Visio源文件在这里。

